
过去五年里,AI 图像生成技术走了多远?
神译局是36氪旗下的编译团队,关注科技、商业、职场、生活等领域,重点介绍外国的新技术、新观点、新风向。
编者按:近年来,AI生成图像技术已经得到了质的飞跃。作者通过介绍人工智能研究组织 OpenAI 的最新图像生成技术 DALL-E,向读者们展示过去五年里这项研究的发展历程。本文来自Medium,作者Dave Gershgorn,原文标题:Take a Look at How Far Image Generation A.I. Has Come in Just 5 Years。

图片来源 Getty Images|摄影 xia yuan
OpenAI (一个非盈利的人工智能研究组织——译者注)现在已经成为了人工智能工业体系中最具未来感的原型。
这家由微软支持的研究机构是创业孵化器 Y Combinator 的项目,机构创始人是山姆·阿尔特曼(Sam Altman)。该机构以强大的文本生成器 GPT-3 而闻名业界。近几年来,它还制造了一个可以通过自主学习解魔方的机器手,一个可以谱曲的、为游戏提供复杂策略的算法。
不久前,OpenAI 又发布了名叫 DALL-E 的新系统,这是一种可以基于书面文本自动生成图像的系统。例如,输入文字“牛油果形状的皮革钱包”,该系统就会通过这一指令进行数次迭代,最终生成各类图像。
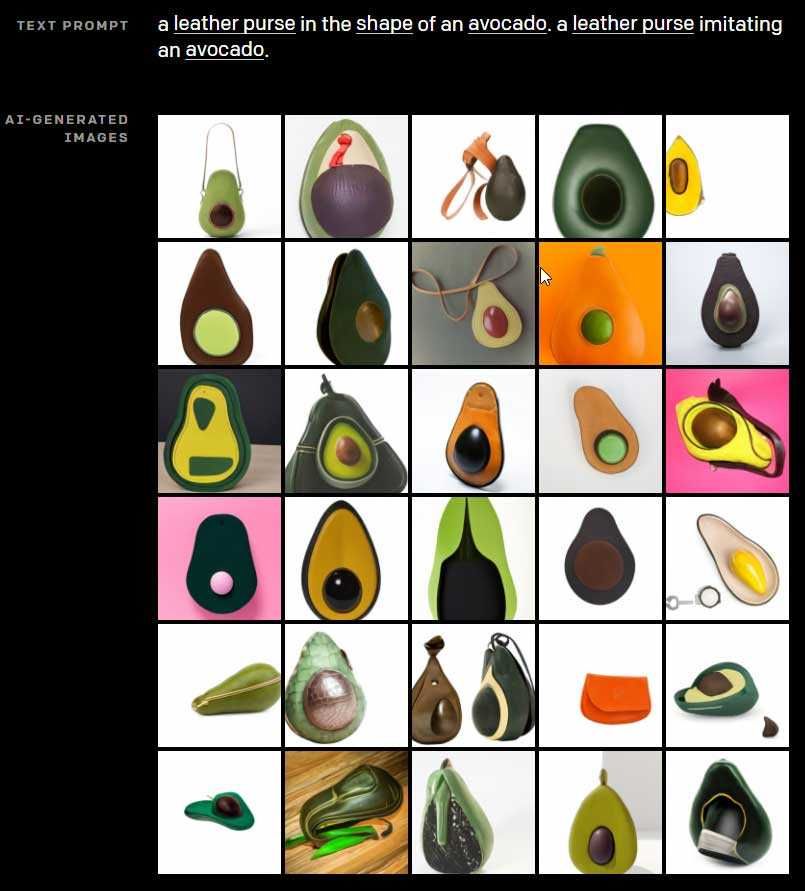
图片来源 :?OpenAI
DALL-E 的名字灵感来自超现实主义画家萨尔瓦多·达利(Salvador Dalí)和动画形象 WALL-E。此次发布新系统时,公司并未将系统对公众开放,甚至没有邀请特定的开发人员尝试系统。但其网站上的图画表明,该系统已经能够创建极其逼真细致的图像了。
DALL-E 还可以生成各种风格的图像,包括插图和风景。它还可以在图片上生成一些文本,比如在建筑上建立文字标志,或者在制作草图和全彩成品图之间作区分。
人工智能研究人员将这种技术称之为泛化技术(generalization,有时也称作概念化技术——译者注),因为这种技术意味着算法对每一项指令多会进行多种风格的创作,而不会满足于特定的某一种风格。
OpenAI 的算法之所以如此熟练,要归因于两个因素。首先,这种算法使用了120亿参数,这使得它能更快的理解文本内容。在分析文本的过程中,这120亿参数可以使它生成精确、令人惊叹的图像作品。
其次,将图像和文本资料放进算法里也是有讲究的。一言蔽之,这些图像和文本都被转化成了算法更容易理解的文本或Token令牌。
在 OpenAI一篇关于DALL-E的博客文章上,作者这样解释Token令牌:它们代表了一种碎片化的、更易于电脑读取的概念,一种专门为算法设计的语言。这种计算机语言字母表包含了个和文本有关的Token令牌,还有8192个和图像有关的Token令牌。这种将人类可读文本自动转换成机器可读文本的方法被称之为“transformer 模型”。
当我们给算法一个文本或者一个图片注释时,人类语言会被转化成不超过256个Token令牌,图片会被转化为最多1024个Token令牌。这使得算法可以通过较少的文本匹配较复杂的图像。
最后,这种算法会通过分析图像和图片注释进行学习。通过数百万次的迭代,它可以将文本片段和图像的特点相关联。OpenAI 此次并没有发布关于数据集大小和图像内容的相关信息。
该公司不是第一个致力于研究文字生成图像技术的公司,只不过该公司推出的是算法类别的最新版本,目前来说功能或许是最强大的。虽然公司尚未发布描述该系统的相关文章,但该算法的创建者的确在其博客文章中描述了 DALL-E 的前身。通过对这一算法发展状况的观察,我们可以追踪到这一技术的发展状况。
2016年OpenAI 曾引用了密西根大学和马克斯·普朗克研究所的一篇关于文本生成图像的研究论文,这篇论文讲述了如何通过生成对抗网络(generative adversarial networks, 简称GAN)来生成图像。简言之,这种方式会使用两种算法以对抗的方式生产图像:第一个算法生成图像,如果该图像不够真实,那么第二个算法就会驳回图像。

图片来源 :?Reed et. al
2017年一年后,罗格斯大学、利哈伊大学和香港中文大学的研究人员采用了另一种生成对抗网络法,这一次他们将成对的算法“堆叠”起来。第一组算法对场景的形状和颜色布局,然后第二组算法再对细节进行细化。

图片来源 :?Zhang et. al
2019年到2019年,一个隶属于微软的团队开始尝试一种与众不同的“两步法”:第一步是生成一个仅显示对象所在位置的地图,第二步是通过上述地图,再生成具体的对象。