
基于深度学习的图像增强综述
作者:木瓜子
文章转自知乎,著作权归属作者,侵删
来源丨 Photos on Mobile Devices with Deep Convolutional Networks
这是ICCV2017年的一篇文章,Ignatov等人自己构建了一个大的数据集(DPED),包含6K多张照片,使用三部手机和一部单反在多种户外条件下同时拍摄得到。然后作者针对这三个成对的数据集,提出了一种新的图像增强算法。通过学习手机拍摄的照片和单反照片之间的映射关系来将手机拍摄的照片提升到单反水平,这是一个端到端的训练,不需要额外的监督和人为添加特征。其网络结构采用的是GAN模型,如下:
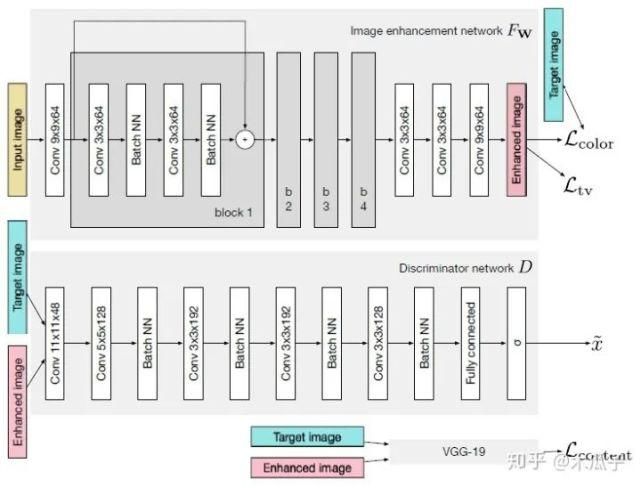 如图所示,GAN主要由两个网络组成,一个生成网络G和一个判别网络D,整个网络是一个对抗的过程,G不断生成能欺骗D的数据,D不断提高自己辨别真假的能力,直到达到一个均衡状态。这里的输入图像是手机拍摄的照片,目标图像是单反拍摄的照片,它们是一一对映的关系。生成器CNN结构,首先输入一张图像,经过一个卷积层预处理后,使用了4个残差块,再经过3个卷积层得到增强后的图像;判别器CNN用于判断增强后的图像和目标图像的真假,生成器生成的图像要尽可能地欺骗判别器,这样就表明生成的图像与目标图像越接近,也就是增强后的图像效果越好。
如图所示,GAN主要由两个网络组成,一个生成网络G和一个判别网络D,整个网络是一个对抗的过程,G不断生成能欺骗D的数据,D不断提高自己辨别真假的能力,直到达到一个均衡状态。这里的输入图像是手机拍摄的照片,目标图像是单反拍摄的照片,它们是一一对映的关系。生成器CNN结构,首先输入一张图像,经过一个卷积层预处理后,使用了4个残差块,再经过3个卷积层得到增强后的图像;判别器CNN用于判断增强后的图像和目标图像的真假,生成器生成的图像要尽可能地欺骗判别器,这样就表明生成的图像与目标图像越接近,也就是增强后的图像效果越好。
图像增强的主要难点之一是输入图像与输出图像不能密集匹配(pixel-to-pixel),因此标准的均方误差不太适用,本文的另一个贡献是提出了复合的损失函数,包含内容、纹理和色彩三部分。
色彩损失用于衡量增强后图像与目标图像的色彩差异,对图像先做高斯模糊再计算它们的欧式距离,这样的好处是可以消除纹理和内容的影响来评估两图像间的亮度、对比度和主要颜色差异,可以写成如下形式:
其中,Xb, Yb分别是为X,Y经过模糊的图像,如下:
二维高斯模糊算子可以写成如下形式,其中A=0.053, μ=0, σ=3,
使用生成对抗网络(GANs)来衡量纹理质量,因此纹理损失定义为:
FW ,D分别表示生成和判别网络。
计算预训练好的VGG19网络ReLU层后激活的feature map的欧式距离作为内容损失,可以保留语义信息,定义为:
此外,还使用全变分(TV)来增强生成图像的空间平滑性,由于它占的权重比较小,不会影响图像的高频部分,且可以抑制一定程度的椒盐噪声,定义为:
总的损失函数为:
最终要优化的目标函数如下,W为网络要学习的参数,L为总的损失函数,
最后的结果如下:
这篇文章提出了一个照片增强的算法,将手机照片提升到单反水平,使用的数据集DPED均为自然图像,有实际的应用价值。但也存在一些问题,有一些复原后的图像存在色彩偏差或者对比度过高,显得不太自然。此外,文中使用GAN在复原高频信息时不可避免地会放大噪声。最大的缺点是它对每种不同手机的数据集都要重新训练,是一个强监督的过程,通用性不强,后续的工作也对这一算法进行了改进,提出了一种弱监督的方法。
WESPE: Weakly Supervised Photo Enhancer for Digital Cameras
这是CVPR Workshops2018上的一篇文章,是基于上一篇论文的改进,同一个作者写的。上一篇论文中最大的局限性是它对每一个数据集都要重新训练一个模型,不具有通用性,因此这篇文章中,作者提出一个新的弱监督的网络模型WESPE,输入数据和输出数据分别为低质量图像和高质量的图像,但它们在内容上不需要对应,使用一个传递性的CNN-GAN结构来学习它们之间的映射关系,其网络结构如下:
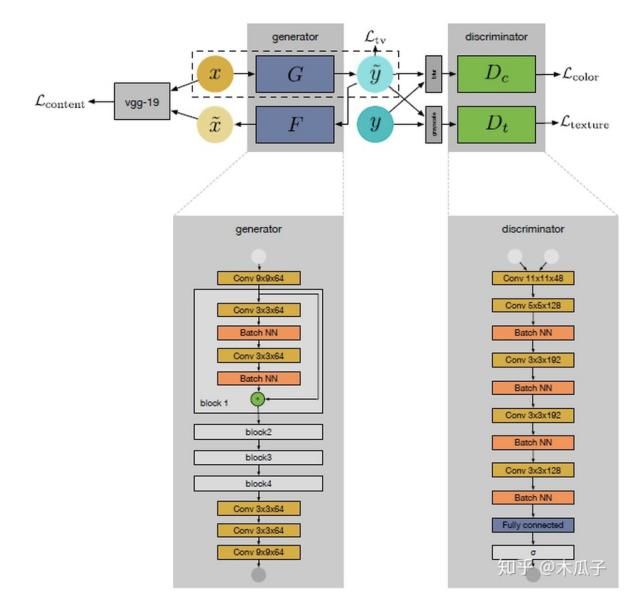 我们的目标是要学习源图像X到目标图像Y映射关系,如图所示,这个网络包含一个生成器映射
我们的目标是要学习源图像X到目标图像Y映射关系,如图所示,这个网络包含一个生成器映射
一个逆生成映射
, 这里的G可以看成图像增强器,可视为退化器,为了保证x与 widetildex
内容的一致性,使用VGG19计算内容损失,这样就可以避免成对的需要内容完全一致的数据集。右侧的两个判别器Dc, Dt分别用于判别增强后图像与目标图像在颜色和纹理上的差异,最后计算TV损失来得到较平滑的图像。
内容一致性损失,计算原图x与
idetildex
在VGG19上某一高 维feature map的L2范数,计算公式如下:
判别器颜色损失,计算增强后的图像与目标图像高斯模糊后的差异,如下:
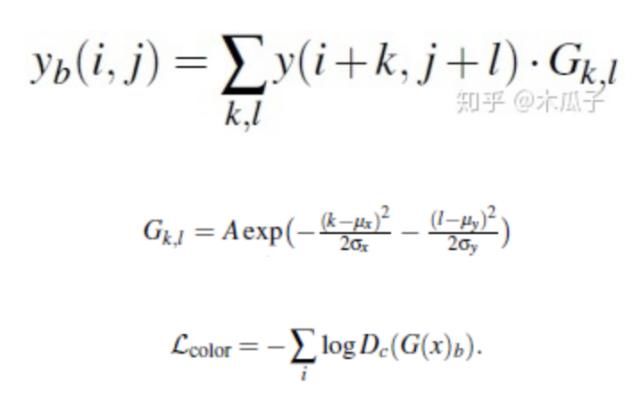 判别器纹理损失,比较增强后图像与目标图像在灰度状态下的损失,定义为:
判别器纹理损失,比较增强后图像与目标图像在灰度状态下的损失,定义为:
TV损失,为了使生成后的图像比较平滑,定义为:
总的损失为: